0x01 什么是正则表达式
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如 a 到 z 之间的字母)和特殊字符(称为”元字符”),是计算机科学的一个概念。
本文使用
https://regexr-cn.com/在线正则表达式测试平台进行测试
在开发和安全领域中,正则表达式有着非常多的应用场景。
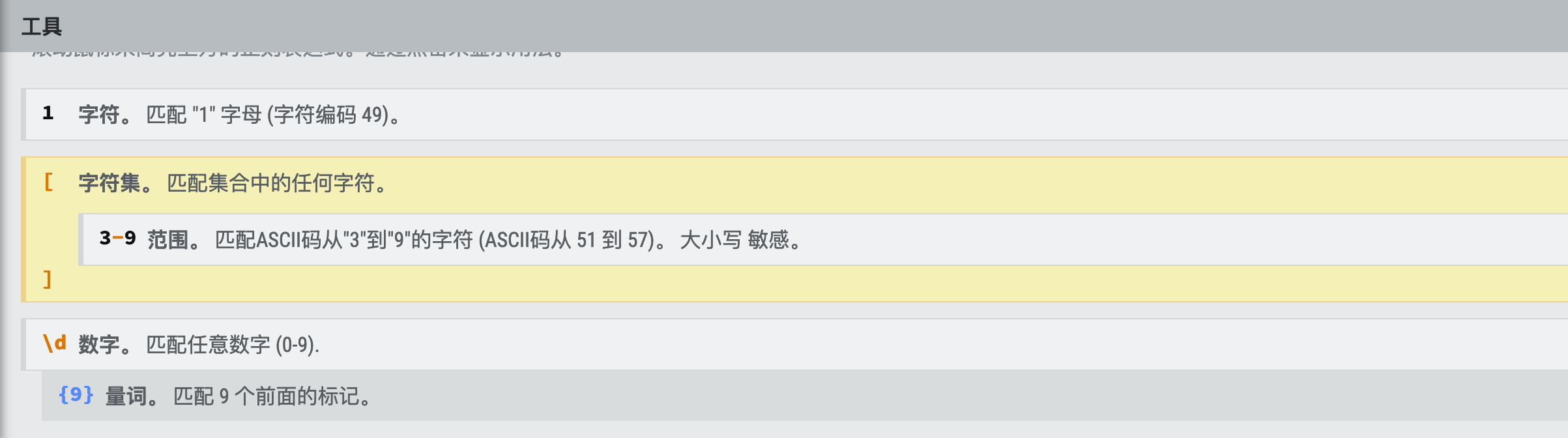
开发场景中使用正则去验证用户输入的手机号是否正确。判断11位手机号的组成是否为:第一位为1,第二位为3-9中的某一个数字,加上9位数字的组成。

安全领域中的 Web 应用防火墙(Web Application Firewall,WAF)就常用正则表达式检测是否命中危险规则,从而进行拦截。
如下就是一个拦截跨站脚本漏洞特征的一个正则,拦截包含alert(、promt(、confirm(特征的语句。

总的来说,正则表达式可以帮我们匹配有规律结构的特征,快速提取想要的数据。
0x02 正则表达式入门
基础入门
普通字符代表单独的一个字符,可以直接使用。

那如果想更加灵活一点,匹配任意小写字母+123的组合。就可以使用字符集[],并在里面给出字符或范围。

如果想匹配任意字母、数字 + 123的组合,就可以[a-zA-Z1-9]表示一个范围。

不过很多场景是通用的,比如[0-9a-zA-Z]这个组合就是匹配所有字母和数字,[0-9]就是匹配数字,那还有一些不可见字符,例如回车、换行、制表符…如何简化这些常用的写法?并且展示这些不可见字符。
元字符表
| 字符 | 描述 |
|---|---|
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9] |
| \D | 匹配一个非数字字符。等价于[^0-9] |
| \f | 匹配一个换页符。等价于\x0c和\cL |
| \n | 匹配一个换行符。等价于\x0a和\cJ |
| \r | 匹配一个回车符。等价于\x0d和\cM |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v] |
| \S | 匹配任何非空白字符。等价于[^ \f\n\r\t\v] |
| \t | 匹配一个制表符。等价于\x09和\cI |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK |
| \w | 匹配包括下划线的任何单词字符。等价于[A-Za-z0-9_] |
| \W | 匹配任何非单词字符。等价于[^A-Za-z0-9_] |
特殊字符表
| 字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。 |
| * | 匹配前面的子表达式零次或多次。 |
| + | 匹配前面的子表达式一次或多次。 |
| . | 匹配除换行符 \n 之外的任何单字符。 |
| [ | 标记一个中括号表达式的开始。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。 |
| { | 标记限定符表达式的开始。 |
| | | 指明两项之间的一个选择。 |
限定符
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 “do” 、 “does”、 “doxy” 中的 “do” 和 “does”。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 “Bob” 中的 o,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 “Bob” 中的 o,但能匹配 “foooood” 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 “fooooood” 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
简单匹配数据
匹配一个常见的 PHP Shell 规则,由$、()和;组成的特定规律。

匹配日期格式,主要匹配年月日yyyy-mm-dd的格式。

通过上面两个简单的例子,可以看出正则非常的方便、快速的匹配出想要的规则,但如果涉及到更复杂的规则就需要一些进阶技巧。
0x03 正则表达式进阶
分组与捕获
有时候我们想匹配的数据没什么规律,但前后数据有规律,不过我们只想获得数据本身,不包括前后多余的字符,最常见的就是在 HTML 标签中的提取任务,这种情况分组功能,一般使用()表示一个分组。分组和捕获在正则表达式中有着密切的联系,一般情况下,分组即捕获,都用小括号完成。
- (exp) :捕获分组,并捕获该分组匹配到的文本
- (?:exp) :非捕获分组,但不捕获该分组匹配到的文本
捕获就是使用小括号指定一个子表达式后,子表达式匹配的文本(即匹配的内容)可以在其他子表达式中重复使用。
这里提取div标签中的内容。使用分组便可获取内容,如果提取的数据后续并没有重复使用,就可以使用非捕获分组,不占用捕获分组的空间。

回溯引用
使用分组匹配 HTML 标签的时候常常会遇见多个标签嵌套的情况。
要求
- 必须匹配每个
<h1>到<h6> - 不能将包含在两个标题标签内的标签匹配到,如
<span>我是span</span> - 不能匹配格式不正确的标题标签,如
<h3>我是错误的H3</h4>
为了避免前后标签不一致的情况,使用了\1进行回溯引用,引用的就是第一次匹配到的标签号。

断言
断言有四种形式,分别是:
它们只匹配某些位置,在匹配过程中,不占用字符,所以被称为“零宽”。不过零宽这个词都有,所以一般省略。
| 符号 | 名称 | 描述 |
|---|---|---|
| reg(?=exp) | 零宽正向先行断言 | reg匹配的内容后面满足exp规则 |
| reg(?!exp) | 零宽负向先行断言 | reg匹配的内容后面不满足exp规则 |
| (?<=exp)reg | 零宽正向后行断言 | reg匹配的内容前面内容满足exp规则 |
| (?<!exp)reg | 零宽负向后行断言 | reg匹配的内容前面内容不满足exp规则 |
先行(lookahead)和后行(lookbehind):正则表达式引擎在执行字符串和表达式匹配时,会从头到尾(从前到后)连续扫描字符串中的字符,设想有一个扫描指针指向字符边界处并随匹配过程移动。先行断言,是当扫描指针位于某处时,引擎会尝试匹配指针还未扫过的字符,先于指针到达该字符,故称为先行。后行断言,引擎会尝试匹配指针已扫过的字符,后于指针到达该字符,故称为后行。
正向(positive)和负向(negative):正向就表示匹配括号中的表达式,负向表示不匹配。正向使用=表示,负向使用!表示。
正向先行断言
例如对 “a regular expression” 这个字符串,要想匹配 regular 中的 re,但不能匹配 expression 中的 re。就可以使用正向先行断言,规定 re 的后面是什么才进行匹配。

负向先行断言
例如对 “regex represents regular expression” 这个字符串,要想匹配除 regex 和 regular 之外的 re,可以用 re(?!g),该表达式限定了 re 右边的位置,这个位置后面不是字符 g。

正向后行断言
例如对 regex represents regular expression 这个字符串,有 4 个单词,要想匹配单词内部的 re,但不匹配单词开头的 re,可以用 (?<=\w)re,单词内部的 re,在 re 前面应该是一个单词字符。

负向后行断言
例如对 “regex represents regular expression” 这个字符串,要想匹配单词开头的 re,可以用(?<!\w)re。单词开头的 re,在本例中,也就是指不在单词内部的 re,即 re 前面不是单词字符。当然也可以用\bre来匹配。
