0x01 ReDoS 基础知识
正则表达式
正则表达式(Regular Expression, Regex)是由字符(可为英文字母、数字、符号等)与元字符(特殊符号)组成的一种有特定规则的特殊字符串。通常用来匹配一系列有规则的内容。通过正则表达式,我们可以限定这个规则并匹配满足规则的内容。
例如,当我们知道国内手机号组成规律,数字1开头,第二个数字是3-9中的一个数字,再加上9位数字,通过这个规则写出正则表达式就可以匹配满足规则的手机号。
1 | /1[3-9]\d{9}/ |
也可以匹配更加复杂的内容
一个 URL:
1 | /(?:http|https|ftp|mailto|file|data|irc):\/\/[A-Za-z0-9\-]{0,63}(\.[A-Za-z0-9\-]{0,63})+(:\d{1,4})?\/*(\/*[A-Za-z0-9\-._]+\/*)*(\?.*)?(#.*)?/ |
或者一个日期:
1 | /^\d{4}/(0[1-9]|1[0-2])/(0[1-9]|[12][0-9]|3[01])$/ |
由此可见,越复杂的规律,其正则就会越长。
正则表达式就是帮助我们寻找有规律的、满足期望数据的工具,正则表达式内容可以查看另一篇文章:https://huta0kj.github.io/2023/09/17/regex/
DFA、NFA
正则表达式的引擎分为两种,分别是 DFA(确定性有限状态自动机)和 NFA(非确定性有限状态自动机),两种引擎的运行条件就是需要一个正则表达式和一份文本字符串。
两种引擎有着不同的匹配逻辑。
DFA 是用文本去匹配正则,对于文本串里的每一个字符只需扫描一次,比较快,但特性较少;
NFA 则是使用正则表达式去匹配字符串,吃掉一个字符,就把它跟正则表达式比较。一旦不匹配,就把刚吃的这个字符吐出来,一个个的吐,直到回到上一次匹配的地方。
通过描述可以看出来,DFA 的速度会快很多,因为文本中的字符串只会比对一次,但功能较少;NFA 要不断的吃透字符串,虽然很慢但是具有分组、替换、分隔等特性,也支持惰性、回溯、反向引用等模式。
| 引擎类型 | 程序 |
|---|---|
| DFA | awk(大多数版本)、egrep(大多数版本)、flex、lex、MySQL、Procmail |
| 传统型 NFA | GNU Emacs、Java、grep(大多数版本)、less、more、.NET语言、PCRE library、Perl、PHP(所有三套正则库)、Python、Ruby、set(大多数版本)、vi |
| POSIX NFA | mawk、Mortice Lern System’s utilities、GUN Emacs(明确指定时使用) |
| DFA/NFA混合 | GNU awk、GNU grep/egrep、Tcl |
可以看到 PHP、JAVA、Python 等语言使用的就是 NFA 的引擎。
DoS
DoS 攻击(Denial of Service attack)指的是通过故意使目标系统的资源耗尽,从而使该系统无法提供或响应正常服务请求的攻击。其目标是中断或暂停在线服务,而不是盗取信息或入侵系统。DoS 攻击通常是通过影响目标系统的网络或服务器来实现的。
0x02 快速了解 ReDoS
ReDoS(正则表达式拒绝服务攻击)是一种利用正则表达式引擎的性能缺陷来发起的拒绝服务攻击。
攻击者通过构造特殊的输入数据,导致正则表达式匹配过程中产生大量回溯操作,从而消耗服务器的资源,降低系统性能,甚至导致服务不可用。
ReDoS 原理
这里通过可视化的方法去理解 ReDoS 的触发机制。假设一个正则表达式为/A(B|C+)+D/g。

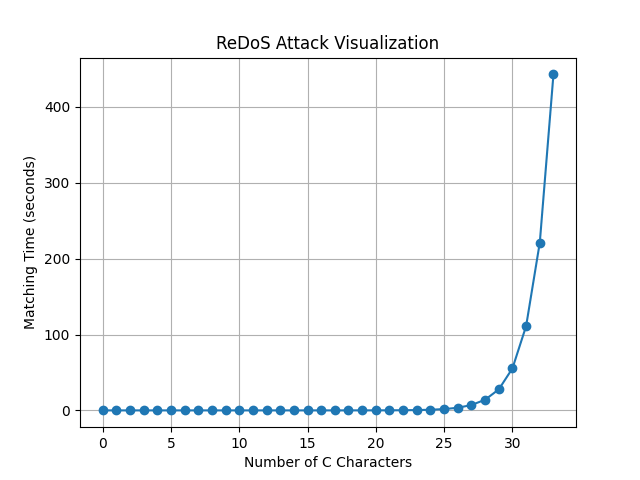
编写一个脚本并可视化图像,通过设置一串文本ABC并不断增加C的个数。
1 | import re |
可以发现,随着C的次数不断增加,匹配时间会呈现指数级的增长,从而耗费计算机资源,这就是 ReDoS 攻击的本质。
首先,我们拆解一下这个正则。
A: 匹配字符A(B|C+): 匹配字符B或者一个或多个连续的字符C+: 匹配前面的模式(B|C+)一次或多次D: 匹配字符D
但这个字符并没有以 D 结尾,所以正则匹配最终会失败。但在试图匹配时,正则表达式引擎会尝试所有可能的组合来看看是否可以成功匹配,特别是在 (B|C+) 和后面的 + 量词之间。
正则会尝试匹配尽可能多的 C,然后再尝试匹配 D。当匹配 D 失败时,它会回溯,并尝试匹配稍微少一些的 C,再尝试匹配 D。这种尝试和回溯的过程会对每个可能的 C 的组合进行重复,导致指数级的尝试次数。这种指数级的回溯也叫做灾难级回溯,导致服务器性能大量降低。
简单案例
以下正则表达式可以匹配由字母和空格组成的字符串,其中每个单词由一个或多个字母组成,单词之间可以有一个空格。
1 | /^(\w+\s?)+$/ |
但如果匹配以下字段的时候,就会引起 ReDoS
1 | word1 word2 word3 word4. |
这是由于(\w+\s?)是一个具有量词的分组。**\w为匹配单词字符,+表示前一个字符1次或无限次扩展,\s表示匹配任意的空白符(包括不可见字符),?表示前一个字符0次或1次扩展**
由于\s?是可选的,每次\w+匹配到一个单词后,正则引擎都需要决定是否继续匹配下一个\w+模式,还是匹配一个空格\s,这种模糊匹配导致了大量的回溯
这里通过regex101查看 regex 的调试过程。
当正则引擎处理到字符串的末尾(即.)时,它会发现不能匹配。这时,它会开始回溯,尝试查找其他可能的匹配方式,短短的几个词经历了158731步回溯。

导致 ReDoS 的原因
使用了具有贪婪、非贪婪或占有性量词的子表达式,如*、+、?、{n,m}等
正则表达式中存在多个分支或可选项,如|、[…]等
使用了循环引用和捕获组
0x03 真实案例分析
Cloudflare ReDoS 中断
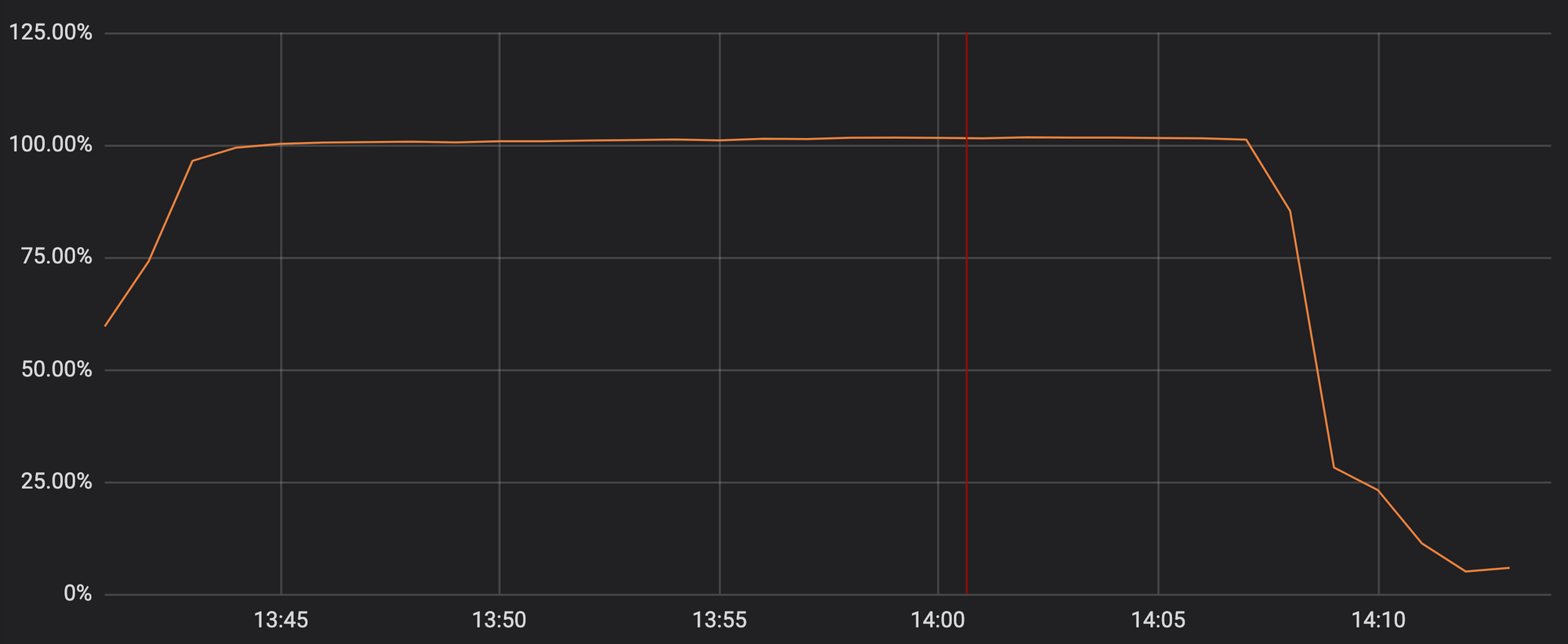
2019年7月2日,Cloudflare 在其 WAF 中部署了新的正则表达式规则。此更新导致全球 Cloudflare 网络瘫痪27分钟,ReDoS 将 Cloudflare 的服务器 CPU 资源提升到几乎100%。
此次 WAF 规则中引起 ReDoS 是由于这段更新的正则。
1 | (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*))) |
其中关键部分是以下部分。
1 | .*(?:.*=.*) |
如果忽略它的模式(非捕获组),它是长这样。
1 | .*.*=.*. |
.*匹配任何字符(除了新行)零次或多次。=匹配字符“=”。.*(再次)匹配任何字符零次或多次。.匹配任何字符一次。
在正则表达式中,.表示匹配单个字符,.*表示贪婪地匹配零个或多个字符(即尽可能多的匹配)所以.*.*=.*表示匹配零个或多个字符。但是第二个.*会匹配=,以至于正则无法在后面文本中找到=,就会进行回溯。
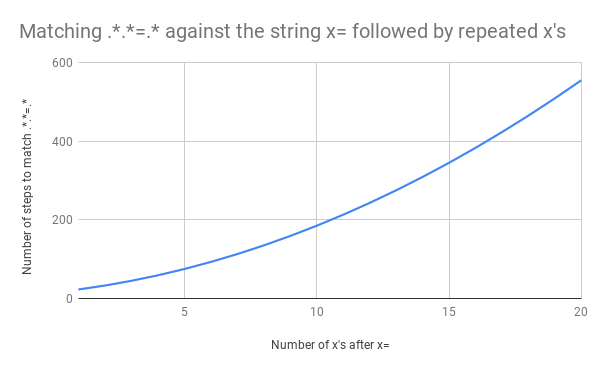
但是对于长的输入文本,回溯匹配数量会指数级增长。
通过 Debug 查看正则匹配过程。
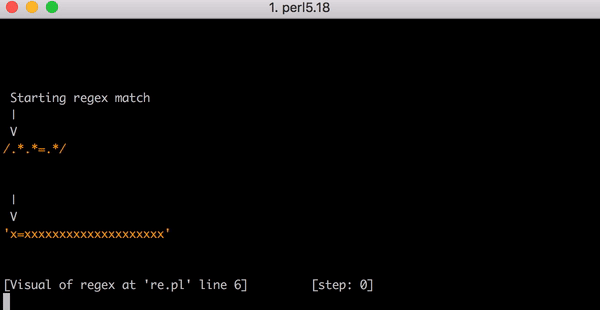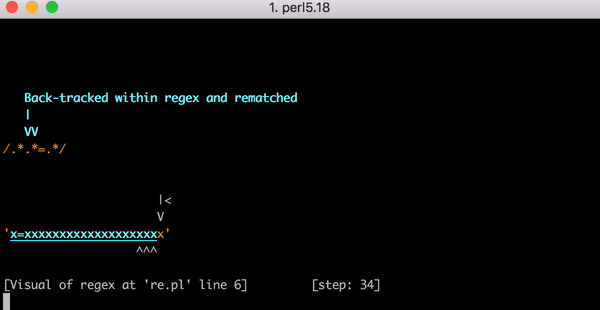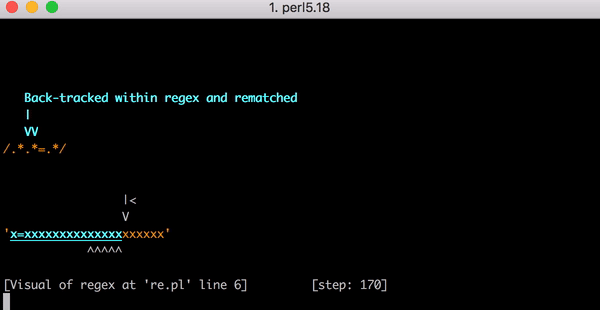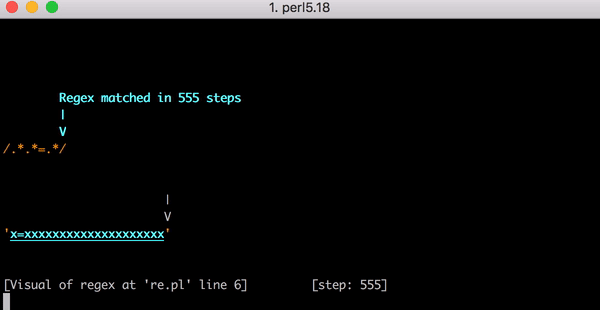
通过图像,匹配 step 会随着x的长度指数级增长。
0x04 如何防范 ReDoS
规范代码和审查流程
- 避免过度回溯:限制或避免使用模糊匹配,例如
.*或.+。这样的模式容易导致大量的回溯。 - 非捕获组:使用非捕获组(例如
(?:...))而不是捕获组(例如(...)),因为捕获组会增加处理时间。 - 限制重复次数:使用
{n,m}来限制字符或组的重复次数,而不是使用*或+。 - 字符集:使用明确的字符集,例如
[a-zA-Z],而不是.。 - 避免嵌套重复:避免使用嵌套的重复模式,如
(a+)*,因为这会导致大量回溯。
在代码提交过程中,对于可能导致 ReDoS 的需要多重 Review。
对于用户可输入的界面,在代码中需要严格显示输入长度。
正则检查工具
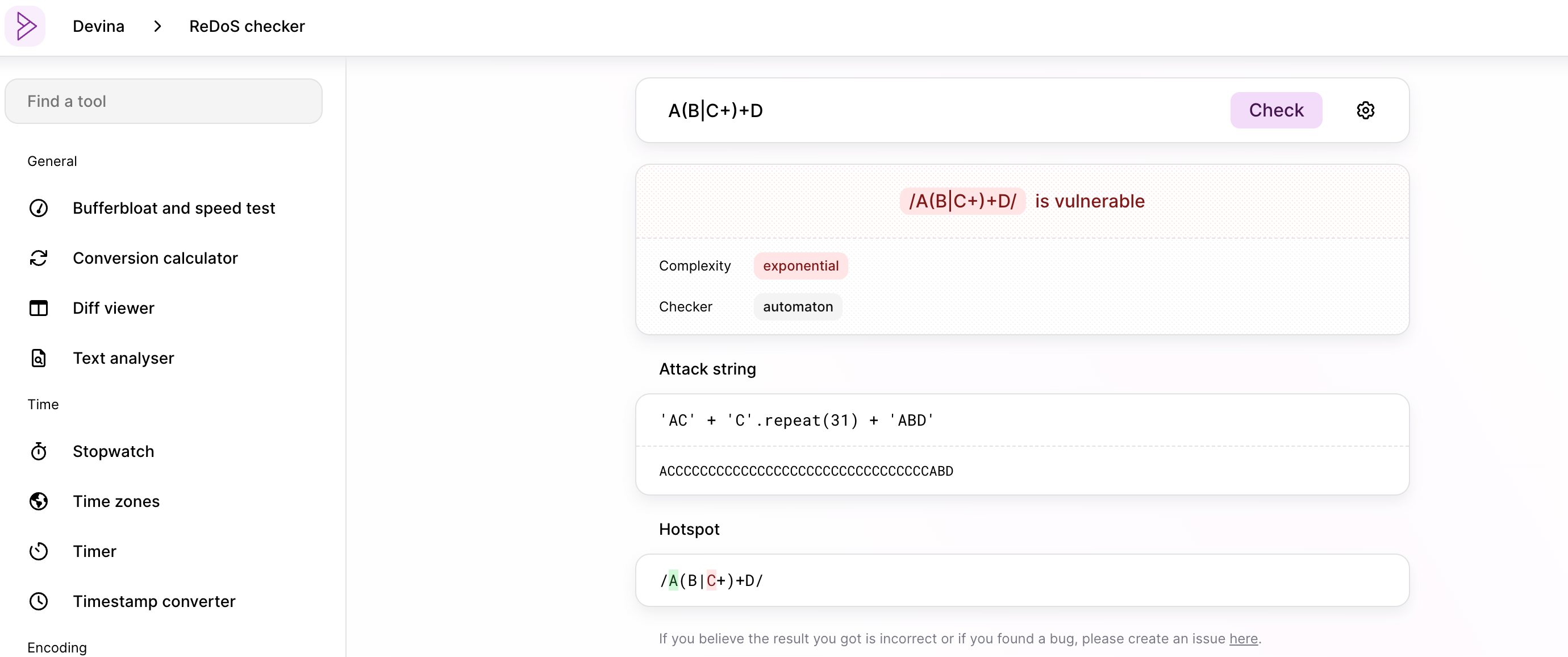
ReDoS Checker
https://devina.io/redos-checker
ReDoS Checker 可以检测正则表达式中是否存在 ReDoS,并给出可以触发 ReDoS 的 payload。
RegexPloit
https://github.com/doyensec/regexploit
RegexPloit 通过提取代码中的正则表达式,并分析其中的正则是否存在 ReDoS。
可以通过以下命令安装。
1 | pip3 install regexploit |
通过 cat 命令查看代码文件,并标准输出给 regexploit。工具会判断是否存在 ReDoS 的正则,并给出触发 payload。

性能监测
Zabbix
Zabbix 是一个企业级分布式开源监控解决方案。能够监控众多网络参数和服务器的健康度、完整性。Zabbix 使用灵活的告警机制,允许用户为几乎任何事件配置基于邮件的告警。基于 Web 的前端页面确保您可以在任何地方访问您监控的网络状态和服务器健康状况。
UMP
UMP 是一款应用性能监控,采集的是应用内部指标,如方法性能、jvm指标、系统存活情况。用运行过程中自行上报方式,收集关键方法的性能(tp99、Max、avg)、调用次数、可用率等数据。
非回溯引擎 PCRE2
PCRE (Perl Compatible Regular Expressions) 是一个开源的正则表达式库,它为许多编程语言提供正则表达式支持,PCRE2 是其后续版本,递归和回溯控制上,PCRE2 提供了更好的控制递归深度和回溯次数的机制,这有助于防止 ReDoS 攻击。